Incremental models in dbt represent a sophisticated approach to managing data transformations efficiently, allowing teams to process only new or changed records rather than recomputing entire datasets from scratch. This methodology significantly reduces processing time and computational costs, especially when dealing with large-scale data warehouses where full table refreshes would be impractical. By leveraging dbt’s built-in incremental logic, data engineers can design pipelines that intelligently identify and merge new data with existing historical data, ensuring that downstream analytics always reflect the most current state of information without unnecessary resource expenditure.
The core mechanism behind incremental models relies on the concept of state management, where dbt keeps track of which records have already been processed and which ones need to be added or updated. This is typically achieved through a unique key and a timestamp or status column that helps filter the incoming data stream. When an incremental run is triggered, dbt compares the new data against the existing target table, performing inserts, updates, or deletes based on the specified configuration. This delta processing capability is crucial for maintaining performance in production environments, as it minimizes the impact on the data warehouse and allows for more frequent data updates without compromising system stability.
To fully harness the power of incremental models, users must understand the various strategies and utilities available within the dbt ecosystem that facilitate this process. From configuring specific incremental materializations to utilizing advanced features like partitions and hooks, dbt provides a robust toolkit for optimizing data pipelines. Understanding these utilities enables data practitioners to build scalable, resilient, and high-performance data models that can adapt to growing data volumes and evolving business requirements, ultimately driving better decision-making across the organization.
The Core Mechanics of Incremental Logic
Defining the Incremental Strategy in Data Pipelines
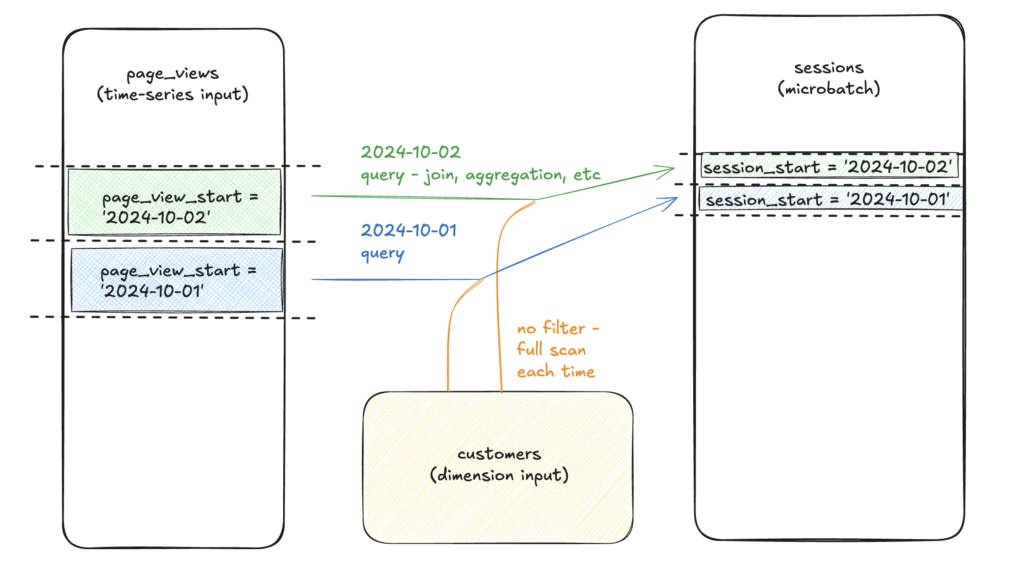
The incremental strategy is fundamentally designed to handle data that grows continuously over time, such as transaction logs, event streams, or daily sales records. Unlike full refresh models that truncate the target table and rebuild it completely, incremental models act as an intelligent merge operation. They respect the existing data in the table and only apply changes where necessary, which preserves the history and integrity of the dataset while appending the latest information efficiently.
The Role of Unique Keys in Record Deduplication
At the heart of every effective incremental model lies the definition of a unique key, which serves as the primary identifier for each record within the dataset. This key allows dbt to determine whether a new row represents a brand new entry that should be inserted or an existing record that requires an update. Without a properly defined unique key, the incremental model risks duplicating data or failing to update correct records, leading to inaccurate reporting and analytical errors.
Configuring the Default Incremental Behavior
By default, dbt simplifies the implementation of incremental logic through standardized configuration options that can be set directly in the model files. Users can specify the materialization as incremental, define the unique key, and set the strategy for handling updates. This default behavior is optimized for common use cases, providing a balance between ease of use and performance, ensuring that even users with minimal coding experience can deploy efficient data pipelines.
Utilizing Built-in Configuration Options for Efficiency
Specifying the Incremental Strategy Parameter
The incremental strategy parameter offers granular control over how dbt physically applies changes to the target table, allowing users to choose between different SQL commands. Options typically include append, insert_overwrite, and merge, each serving distinct performance needs depending on the database platform. Selecting the correct strategy is vital for optimizing query execution plans and reducing the load on the data warehouse during transformation runs.
Leveraging the Partition Configuration for Performance
Partitioning divides a large table into smaller, more manageable segments based on the values of a specific column, such as a date. This configuration allows dbt to scan and update only the relevant partitions rather than the entire table, drastically improving query performance. Utilizing partitions effectively can turn a prohibitively expensive operation into a swift process, particularly in cloud data warehouses like Snowflake, BigQuery, or Redshift where partition pruning is a key performance feature.
Managing Cluster Keys for Distribution
Cluster keys determine how data is physically sorted and stored on disk, which significantly impacts the speed of query execution when filtering or joining tables. By defining cluster keys on frequently filtered columns, such as dates or identifiers, users can enhance the speed of incremental scans. This utility ensures that when dbt searches for records to update, it reads fewer blocks of data, thereby reducing the overall compute time required for the incremental run.
- Strategy Selection: Choosing between append, delete+insert, or merge strategies based on specific data update patterns.
- Partition Pruning: Setting up date or integer partitions to limit the scope of data scanned during each incremental run.
- Clustering Optimization: Defining cluster keys to co-locate similar data on disk for faster retrieval and merging operations.
Advanced Techniques for Handling Data Updates
Implementing the Append Strategy for Purely New Data
The append strategy is the most straightforward method, suitable for datasets that only receive new records and never require updates to existing historical data. In this scenario, dbt simply inserts the new rows into the target table without checking for duplicates or modifications. This approach is incredibly fast and efficient for immutable data logs, event streams, or any data source where records are written once and never changed again.
Applying the Insert Overwrite Method for Replacing Data
For use cases where specific partitions of data need to be completely replaced rather than individually updated, the insert overwrite strategy is highly effective. This method works by deleting the specific partition that contains new data and then inserting the fresh batch in its place. It is particularly useful for correcting errors in specific time periods or handling late-arriving data that necessitates a full refresh of a particular timeframe.
Using the Merge Strategy for Complex Transformations
The merge strategy represents the most flexible and comprehensive approach, capable of handling inserts, updates, and even deletes in a single operation. It utilizes SQL merge commands to compare the source data with the target table based on the unique key and apply the necessary changes. This is essential for transactional data where a record might be created, updated multiple times, or soft-deleted over its lifecycle, ensuring the final table accurately reflects the current state.
- Immutable Logs: Using append-only logic for high-volume event data where historical accuracy is fixed at write time.
- Partition Replacement: Swapping out entire time-based segments to correct historical data or handle reprocessing.
- Upsert Capabilities: Merging new and existing data to maintain a slowly changing dimension type 1 or 2.
Optimizing Performance with Pre and Post Hooks
Pre-Hook Operations for Data Preparation
Pre-hooks are SQL statements that execute immediately before the main incremental model runs, allowing users to perform preparatory tasks such as truncating temporary tables or creating staging views. These hooks are powerful for ensuring the environment is correctly set up for the incremental logic, such as deleting data from a specific partition that is about to be reloaded. By managing the state before the merge, users can prevent conflicts and ensure data consistency.
Post-Hook Actions for Cleanup and Maintenance
Once the incremental model has successfully merged the new data, post-hooks can be triggered to perform cleanup actions, such as vacuuming old data, updating statistics, or granting permissions to specific user roles. These maintenance tasks are crucial for keeping the data warehouse performant over time. Automating these tasks via hooks ensures that best practices are followed consistently after every data build without requiring manual intervention from the data engineering team.
Managing Transactions and Error Handling
Hooks also play a vital role in managing complex transaction flows and error handling within the incremental process. By wrapping operations in transactions or using hooks to log the status of a run, teams can create more resilient pipelines. If an incremental run fails, a pre-hook or post-hook can be configured to handle the cleanup or send alerts, ensuring that the system remains in a consistent state and that failures are addressed promptly.
- Staging Environment: Using pre-hooks to create or refresh staging tables before the incremental merge begins.
- Automated Maintenance: Executing vacuum or analyze commands via post-hooks to optimize table storage after updates.
- Security Enforcement: Applying grants or revoking permissions automatically after data is loaded into the target table.
Debugging and Monitoring Incremental Runs
Interpreting the Run Logs for Performance Insights
Understanding the detailed logs generated by dbt during an incremental run is essential for diagnosing performance bottlenecks and verifying logic. The logs provide a step-by-step account of the SQL execution, including how long each step took and how many rows were affected. Analyzing these logs helps identify whether the incremental filter is working correctly or if a full table scan is occurring unintentionally, which can lead to excessive compute costs.
Utilizing the dbt Docs for Model Lineage
Documentation tools within dbt automatically generate a visual representation of the data pipeline, showing how incremental models fit into the broader ecosystem. This lineage view helps teams understand the dependencies and downstream impacts of any changes made to the incremental logic. By visualizing the flow, data engineers can ensure that the incremental model is correctly sourced and that its outputs are being consumed appropriately by downstream reports and models.
Validating Data Integrity After Incremental Runs
Ensuring that the incremental model has produced the correct result requires rigorous testing and validation against expected outcomes. This involves writing data tests to check for uniqueness, null values, or referential integrity after the merge operation. Validating data integrity confirms that the incremental logic is functioning as intended and that the historical data has not been corrupted or accidentally duplicated during the merge process.
- Log Analysis: Reviewing execution time and row counts to ensure only the expected delta was processed.
- Lineage Tracking: Visualizing data flow to understand dependencies and potential impact areas.
- Automated Testing: Implementing tests to catch anomalies in uniqueness, foreign keys, or value ranges post-merge.
Best Practices for Scalable Incremental Modeling
Designing for Idempotency in Pipeline Execution
Idempotency ensures that running the same incremental model multiple times with the same data does not result in duplicate records or errors. This is achieved by carefully designing the logic to handle re-runs gracefully, often by filtering on the maximum timestamp or using idempotent keys. Building idempotent models is critical for reliability, allowing data teams to rerun jobs without fear of data corruption during debugging or recovery scenarios.
Choosing the Right Partition Granularity
Selecting the appropriate level of granularity for partitioning is a balancing act between query performance and management overhead. While daily partitions offer fine-grained refresh capabilities, they can lead to a large number of metadata objects, whereas monthly partitions might be too coarse for frequent updates. Finding the optimal granularity ensures that the incremental runs are efficient without overwhelming the data warehouse’s metadata catalog or complicating maintenance tasks.
Planning for Schema Evolution Over Time
Data models are rarely static, and schema changes such as adding new columns or changing data types must be handled carefully in incremental models. Best practices involve using mechanisms that allow for backward compatibility or explicitly handling column additions. Planning for schema evolution ensures that the incremental pipeline can adapt to changing business requirements without breaking existing logic or requiring costly full table rebuilds to accommodate structural changes.
- Rerun Safety: Ensuring models can be executed multiple times safely without duplicating data or causing errors.
- Optimal Granularity: Balancing partition size to maximize query performance while minimizing metadata overhead.
- Future-Proofing: Designing schemas that can accommodate new columns and data types without breaking existing pipelines.
Conclusion
Mastering dbt incremental models requires a deep understanding of configuration strategies, database-specific utilities, and performance optimization techniques. By leveraging these powerful tools, data teams can build efficient, scalable, and cost-effective pipelines that handle growing data volumes with ease. Adopting these best practices ensures that your data infrastructure remains robust, agile, and ready to meet the evolving demands of modern analytics.